9.3 聚类分析
聚类是工业数据分析中应用广泛的探索性分析手段。IDMP 支持在散点图面板中对两个属性的数据执行聚类分析,帮助用户在无需预先标注的前提下,自动发现设备运行状态、工况模式或时段特征的自然分组,从而为状态识别、故障归因和优化决策提供数据依据。
9.3.1 聚类原理
聚类是一种无监督学习方法,其核心目标是:在没有类别标签的情况下自动将数据分组,使同一组内的样本彼此相似,不同组之间的样本差异明显。
从数学角度来看,聚类的优化目标可以表述为:最小化簇内离散度(Intra-cluster Variance),同时最大化簇间距离(Inter-cluster Distance)。算法将样本映射到特征空间,通过距离度量(如欧氏距离、余弦相似度等)衡量样本间的相似程度,并以迭代或层次化的方式寻找使上述目标函数达到最优的划分方案。
与分类任务不同,聚类无需提前定义类别体系,也无需标注样本——算法完全从数据的内在分布结构中发现潜在的规律和分组。这一特性使聚类特别适合工业场景中"我们知道状态是多样的,但不确定有几类、每类特征如何"的探索性分析需求。
在 IDMP 中,聚类分析以散点图的 X 轴和 Y 轴所对应的两个属性为输入,在二维特征空间中寻找自然聚集的样本群。聚类结果直观地呈现为散点图上的颜色分区,揭示数据的内在分组结构,为后续的状态建模、异常基线设定和模式对比提供参考视图。
9.3.2 适用场景
聚类在工业领域具有广泛的实用价值,典型场景包括:
- 设备工况识别: 对旋转设备的振动、温度和电流进行多维聚类,自动区分正常运行、轻微磨损、严重异常等工况区间,为预测性维护建立状态基准
- 生产工艺分组: 对工艺过程参数进行聚类,识别与良品率相关的优质工艺区间与问题工艺区间,辅助工艺优化和质量管控
- 用能模式发现: 对电力负荷或能耗数据按时段聚类,识别工作日、节假日、高峰期等典型用能模式,支持需求响应和节能策略制定
- 设备健康分级: 对同类设备的多维运行指标进行聚类,将设备群体自动分为健康、亚健康、异常等层级,辅助资产管理决策
9.3.3 支持算法
工业数据聚类领域有多种经典与现代算法,各自适应不同的数据结构和应用需求:
| 算法 | 类型 | 特点 |
|---|---|---|
| K-Means | 基于质心 | 将数据划分为 K 个簇,以各簇均值为质心迭代优化;计算效率高,适合大数据量、近似球形分布的场景;需预设簇数 K |
| K-Medoids | 基于质心 | 以实际数据点作为簇中心,对异常值的鲁棒性优于 K-Means;适合含噪声的工业数据 |
| DBSCAN | 基于密度 | 无需预设簇数,通过核心点与邻域半径自动发现任意形状的簇;能将低密度区域的点识别为噪声,适合异常检测与形状不规则的聚类 |
| 层次聚类(Hierarchical) | 基于层次 | 自底向上(凝聚)或自顶向下(分裂)地构建聚类树(树状图);无需预设簇数,可通过截断树状图灵活选择粒度,适合需要探索多层级分组结构的场景 |
| GMM(高斯混合模型) | 基于概率 | 假设数据由多个高斯分布混合生成,通过期望最大化(EM)算法估计参数;支持软分配(样本属于各簇的概率),适合边界模糊、分布重叠的工况数据 |
| Spectral Clustering | 基于图论 | 将数据映射到图拉普拉斯矩阵的特征向量空间后再聚类,能够处理复杂的非线性流形结构;适合拓扑形状复杂的高维数据 |
算法选择建议
- 对于大多数工业多维属性数据,优先选择 K-Means,计算高效,结果易于解释
- 对于含有噪声点或异常样本的数据,选择 DBSCAN 或 K-Medoids 以提高鲁棒性
- 对于不确定分组数量、需要探索数据层级结构的场景,选择层次聚类
- 对于簇边界模糊、工况状态有重叠过渡的场景,选择 GMM
- 对于高维、非线性特征分布的场景,选择 Spectral Clustering
9.3.4 使用入口
聚类分析有两种使用入口。
第一种,通过散点图面板在查看模式下的操作栏中的聚类分析图标进行访问。
步骤:
- 打开或创建一个散点图面板,配置 X 轴和 Y 轴属性,使面板以散点形式呈现两个属性的联合分布。
- 在面板的查看模式下,点击操作栏中的聚类分析图标。
- IDMP 将自动对当前图表中的数据点执行聚类,并以不同颜色区分不同的簇,直观呈现数据的自然分组结构。
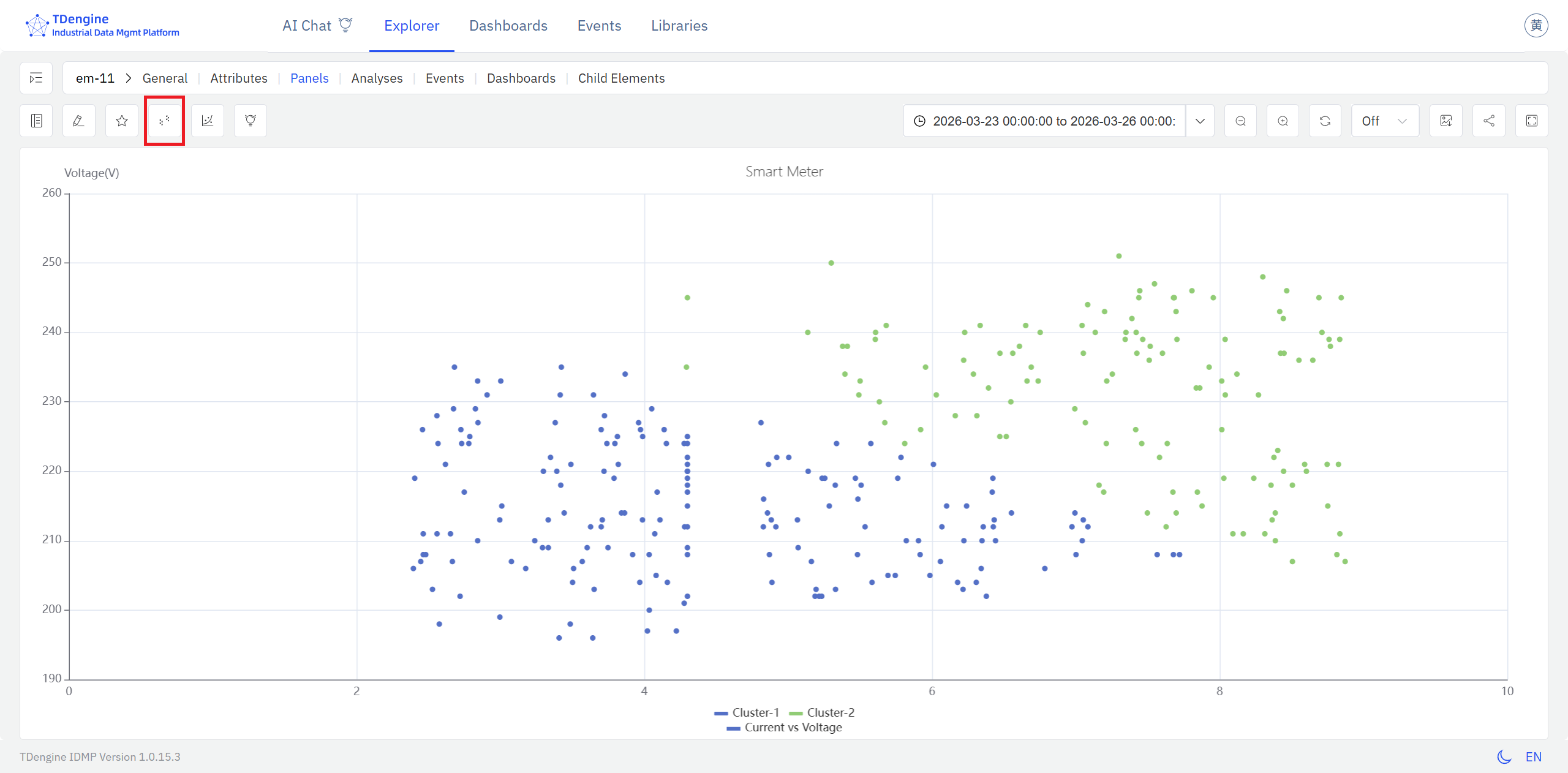
聚类结果叠加在原始散点分布之上,不同颜色代表不同的数据簇,使分组结构一目了然。结合 X 轴和 Y 轴所代表的物理量含义,可以直接读取各簇对应的工况区间范围,为状态标记和进一步分析提供直观的参考视图。
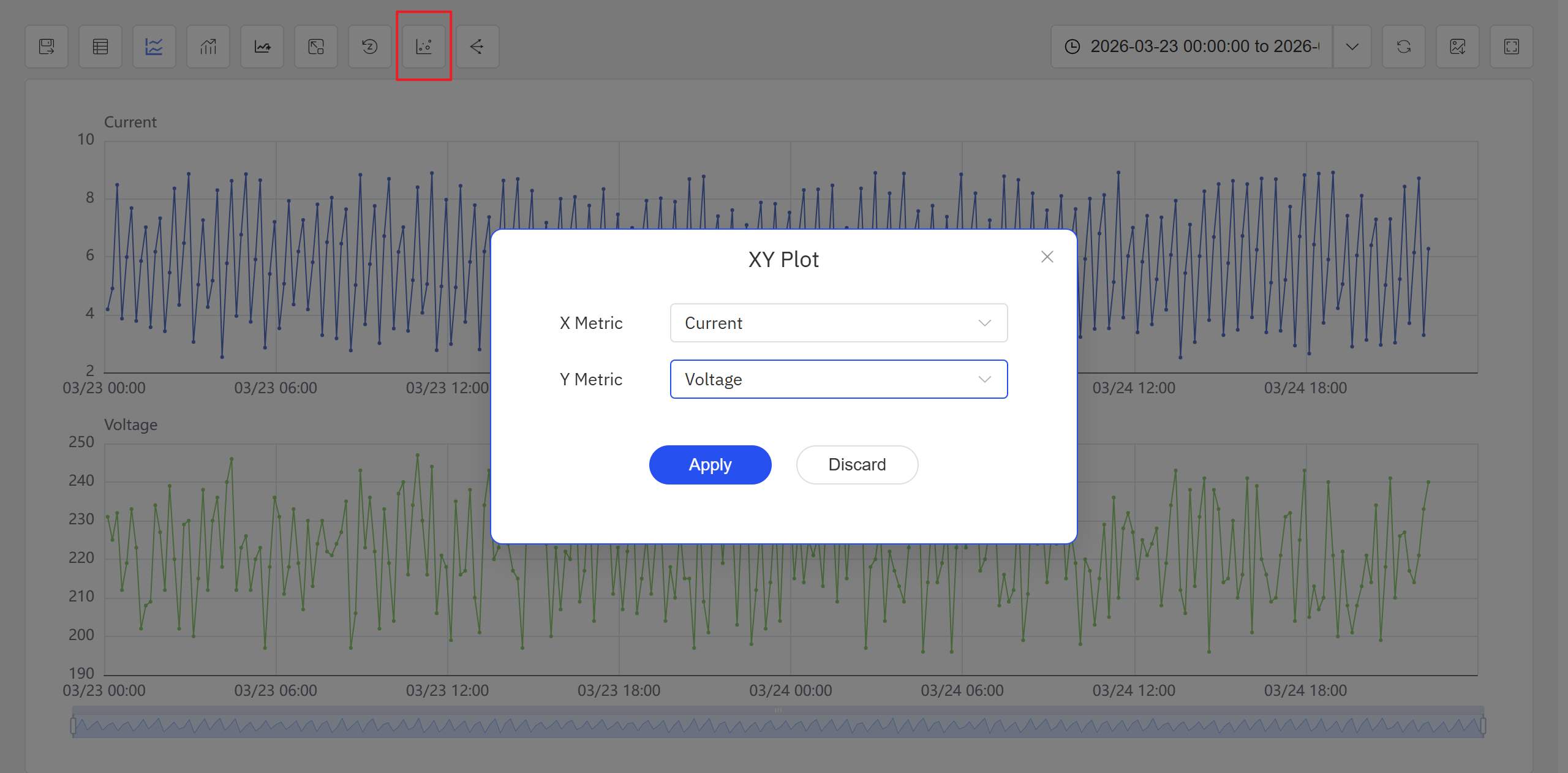
第二种,通过分析工作台操作栏中的启用 XY Plot 图标进行访问。
步骤:
- 打开或创建一个分析工作台,点击启用 XY Plot 图标,在弹出框内选择 X 轴与 Y 轴属性,点击应用,此时面板将变成散点图形式。
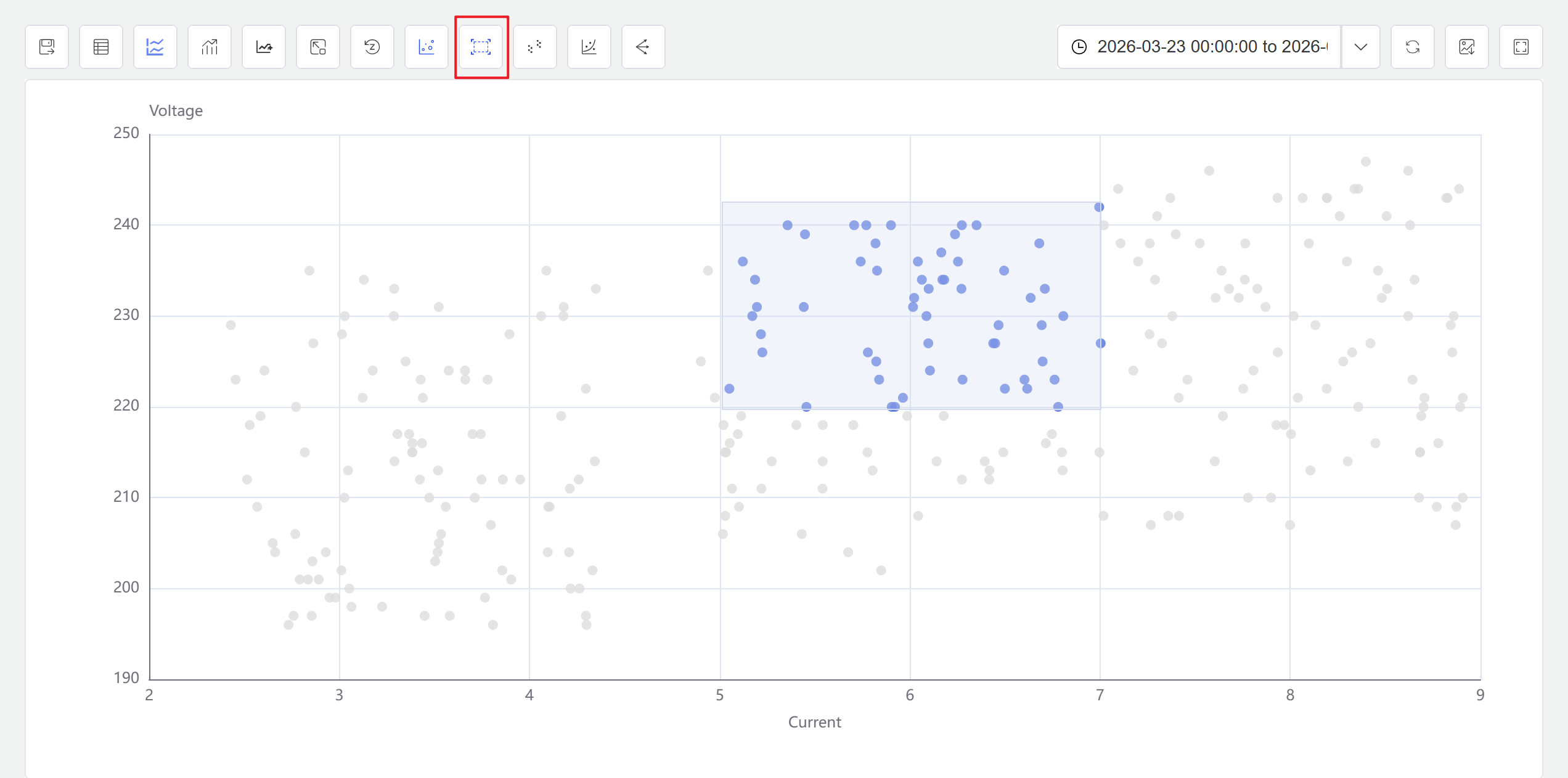
- 点击操作栏的启用框选图标,此时可以用鼠标在散点图内框选数据范围,系统将基于选中的数值点自动生成新的窗口分析。
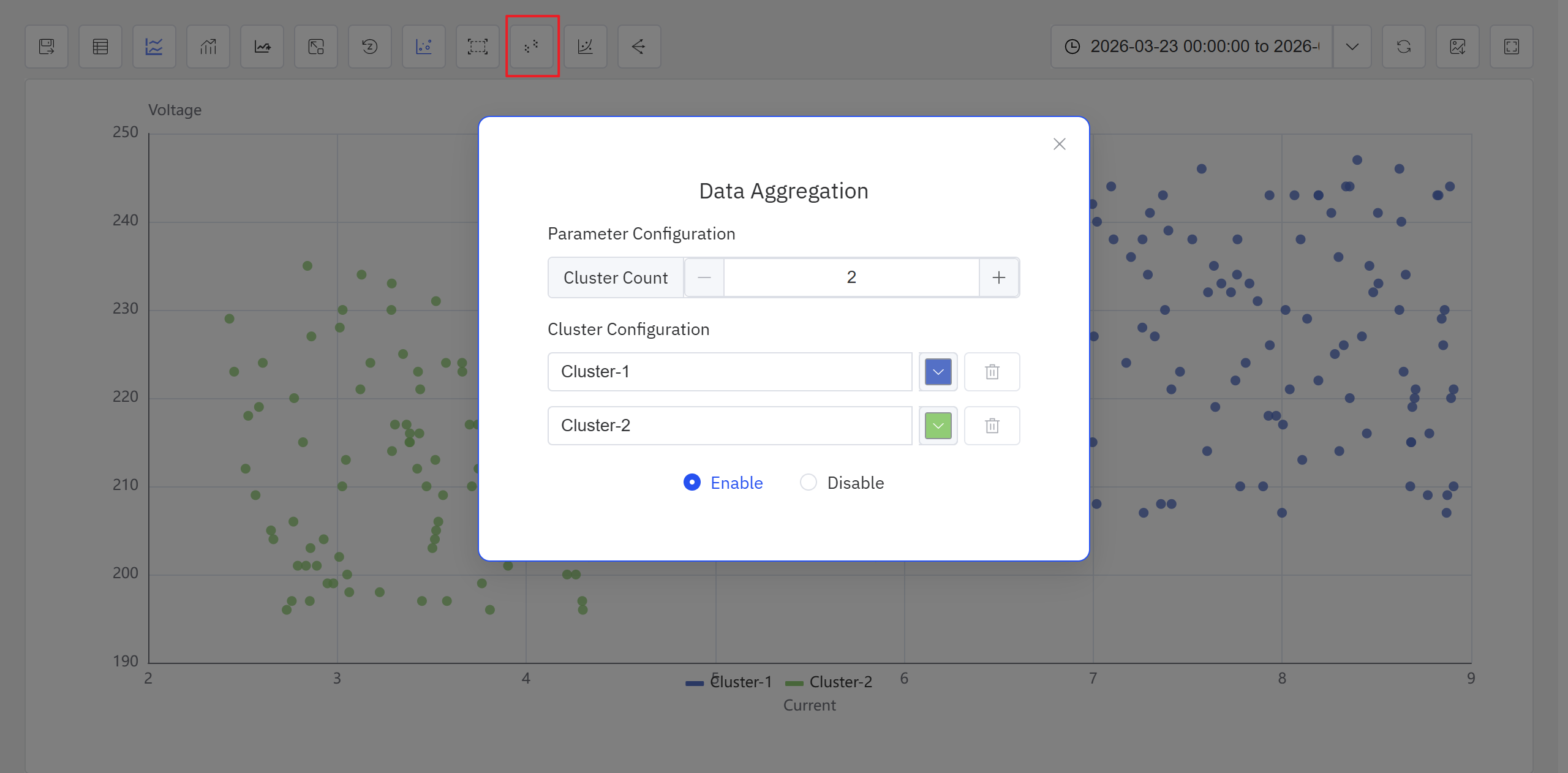
- 点击操作栏的聚类分析图标,在弹出框内确定聚类分析配置后,系统将生成聚类分析结果,并在散点图中用不同颜色显示。
当前版本中,聚类分析的使用入口为分析工作台与散点图面板查看模式操作栏中的聚类分析图标。未来版本将继续扩展算法类型和使用方式。
散点图面板在查看模式下的操作栏还提供回归分析图标,可对散点数据拟合线性、指数或多项式曲线。关于散点图面板的完整配置说明,请参阅散点图章节。
9.3.5 使用示例
场景背景
某风电场运维团队对一批风机进行日常巡检分析。风机在正常运行时,风速与发电功率之间存在稳定的对应关系(功率曲线);一旦叶片结冰、偏航故障或限功率控制介入,这一关系会出现明显偏离。团队希望用一种直观的方式,快速判断某台风机在过去一段时间内是否存在异常运行区间。
操作过程
- 打开或新建一个散点图面板,将 X 轴配置为
风速,Y 轴配置为有功功率,数据源选择目标风机近 7 天的历史数据。 - 在面板的查看模式下,点击操作栏中的聚类分析图标。
- IDMP 对散点数据执行聚类,以不同颜色标记各簇。
分析效果
聚类结果将散点自然分为两到三个区域:大部分数据点集中在符合正常功率曲线形态的主簇,少量数据点形成独立的低功率簇——这些点对应的风速已达到额定出力区间,但实际功率明显偏低。
运维人员据此将这段时间标记为重点复查时段,结合运行日志确认该时段存在偏航系统响应迟滞,安排了校准处理。校准完成后,后续采集的数据显示该风机恢复至正常的功率曲线区间。









