数据建模
使用 IDMP 来管理数据的第一步就是要建立数据资产模型。数据都存储在数据库里,但数据库只是多个二维的表格,表格之间的关系无法直接感知。数据建模的目的就是帮助用户建立起这些二维表之间的关系,以便于管理、查找、分析所拥有的数据。
数据目录
因为企业一般采用树状的组织管理结构和资产管理结构,因此 IDMP 采用树状层次结构来管理数据资产,建立起数据目录 (Data Catalog)。树状结构的每个节点都对应一个元素,类似计算机文件系统的一个目录。这个目录除自身的数据文件之外,还容许有 0 到多个子目录,即子元素。一个元素可以是具体的设备,设备的子系统,也可以是逻辑的实体或组织。通过树状结构的数据目录,用户可以很容易浏览他拥有的数据资产。
建模的过程就是不断创建元素、构建数据目录的过程,形成的树状结构可以对应真实世界里管理的层次结构。比如一个电力集团有多个风力发电厂,每个风电厂有很多台风机,多台逆变器。因此先可以创建“所有电厂”这个元素,在“所有电厂”这个元素下,创建多个风电厂元素,比如风电厂-A,风电厂-B。在风电厂下面,再创建多个风机和逆变器,比如风机-1、风机-2 等。这样数据模型就一级一级的建立起来,如下图所示:
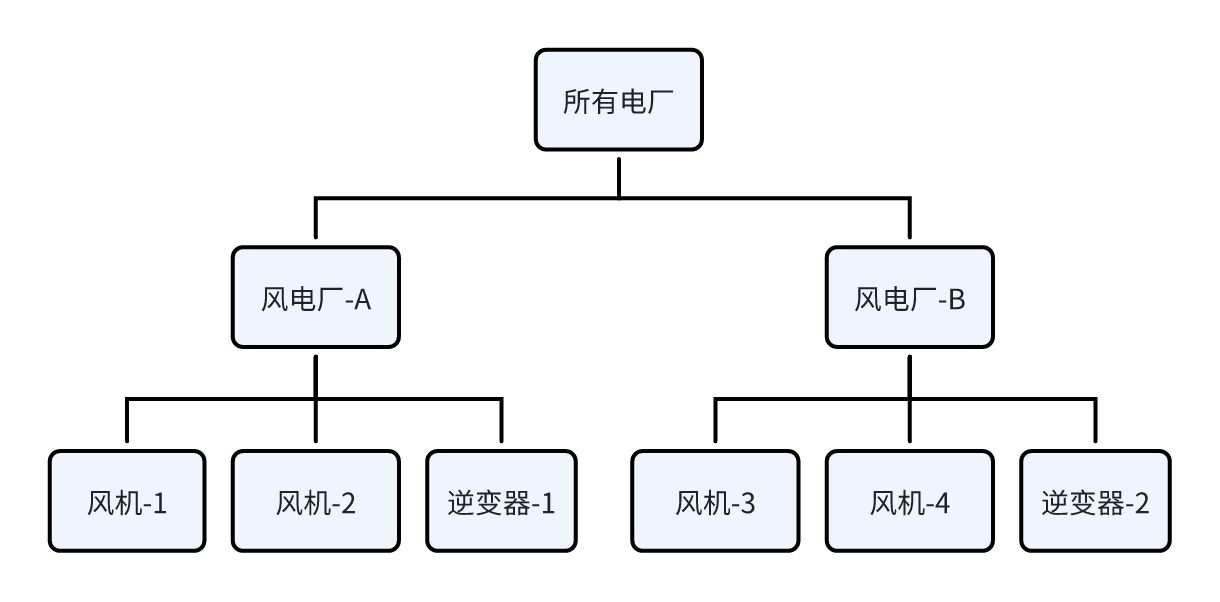
上述是一个从上到下的建模过程。在组织结构不清晰时,也可以实行由下到上的建模过程。比如先创建风机这个元素,等风机配置好一切并工作正常,然后创建风电厂这个元素,再将风机这个元素挪到风电厂这个元素下面。
企业资产管理存在多种组织模式,不同角色需要不同的数据视角,比如负责运营的偏向于按厂来构建树状结构,但负责设备维护的专业团队更喜欢用设备类型来构建树状结构。以风力发电为例,可以构建这样的树状结构:
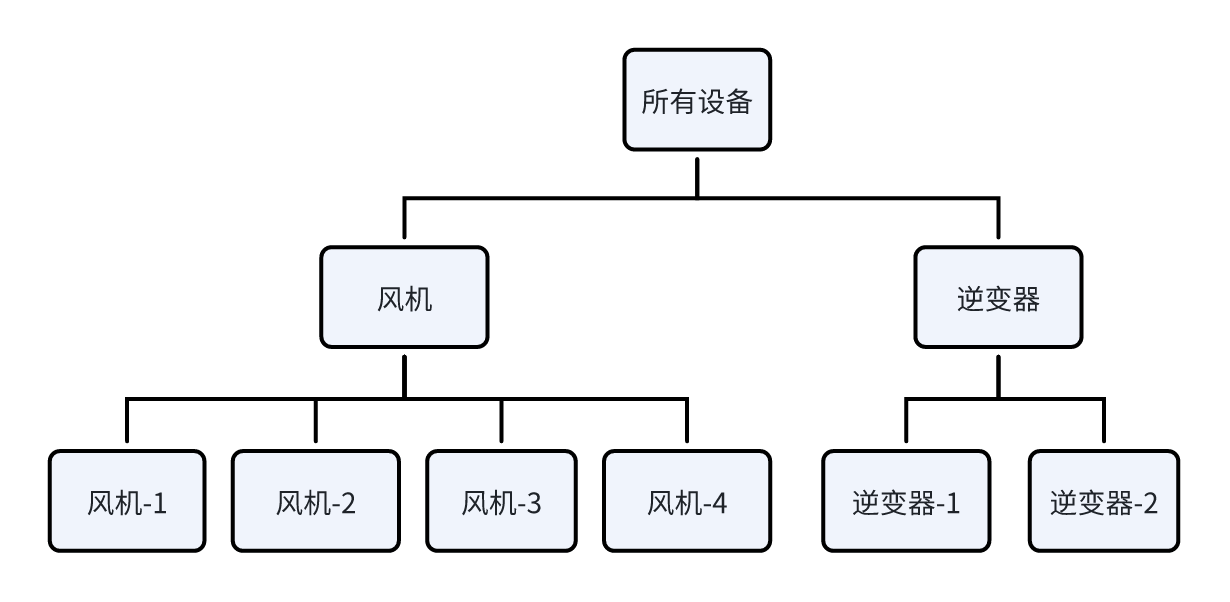
这种层级结构天然契合企业按设备类型进行专业分工的管理需求。 为保证管理的灵活性,IDMP 容许对同一个数据资产构建多个树状结构,一个设备或实体可以通过元素引用的方式属于多个树状结构,这样便于管理。以风力发电为例,可以构建这样的树状结构:
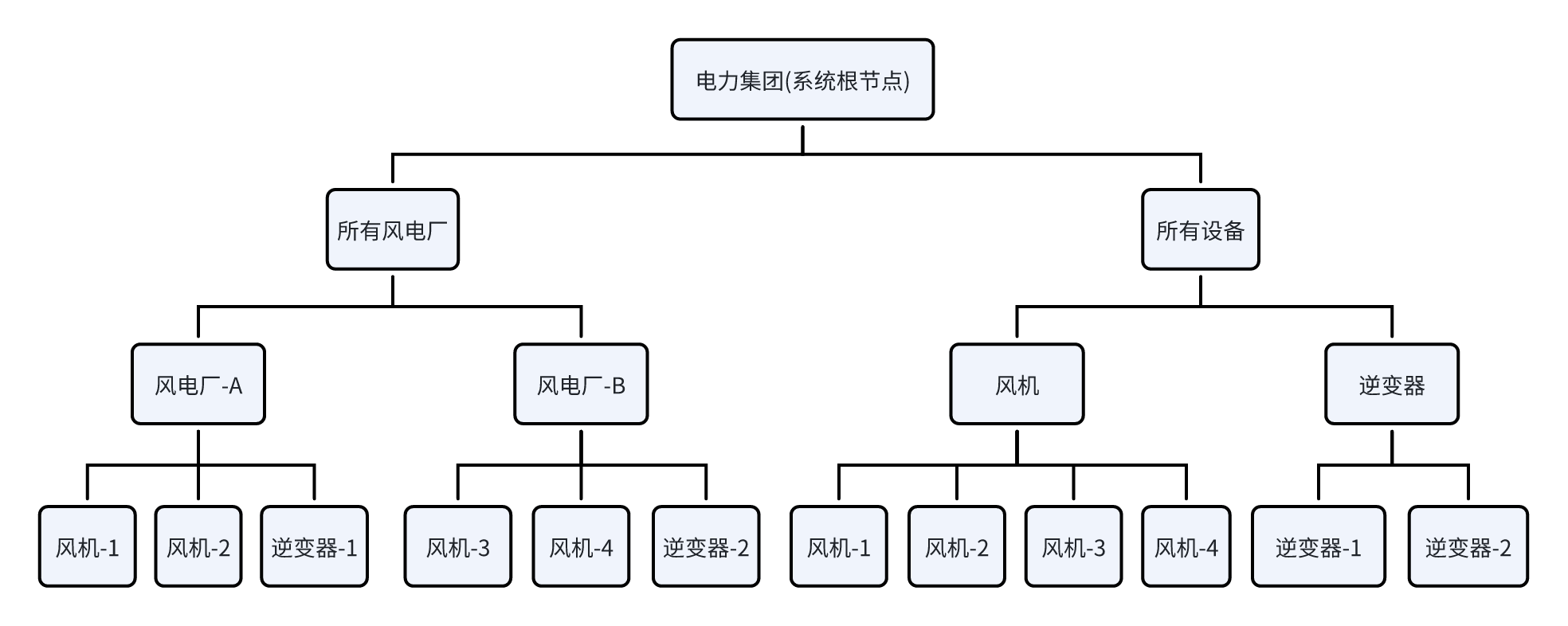
这种设计为不同角色提供了灵活的查看数据方式:
- 厂区管理人员:可通过地理树状结构快速定位管辖范围内的资产
- 专业运维团队:可通过设备类型树状结构集中管理同类设备
因为一个元素可以属于多个树状结构,为减少数据冗余并保证保数据的一致性,IDMP 采用元素引用的机制。元素引用有强引用、弱引用与包含引用三种类型,后续章节将专门介绍。对于第一次使用 IDMP 的用户而言,将一个元素从一个树状结构拷贝到另外一个树状结构时,选择强引用最为简单。
通过支持创建多个并行的树状层次结构,IDMP 完美适应企业多样化的管理需求和组织架构。
元素
在树状结构里,选择一个元素,点击右侧三个点菜单,将出现下拉菜单,再选择“新建子元素”即可在当前元素下创建子元素。这时可以选择元素模板或不选择,可以选定引用关系(缺省为强)。后续高级话题将专门讨论元素引用关系,暂时选择缺省设置“强”,然后一个元素就创建了。
用户可以设置元素的名称、类别 (Category)、位置、描述信息等等。
对于同一类设备,可以先在基础库里创建元素模板,这样便于批量创建和管理元素,而且保证了数据的标准化。
IDMP 还提供元素拷贝、粘贴的功能,便于您创建类型相近的元素。
一个元素创建后,可以被删除、修改。在树状结构里,点击一个元素,您还可以拖拽它到其它节点,产生一个元素引用。这些修改、删除、拷贝、粘贴、挪动操作都是便于您灵活构建和调整树状结构。
属性
一个元素可以拥有很多动态或静态属性。在树状结构之上,只有把每个元素的属性配置好,我们才将真实的物理世界映射到了数字世界,构建了它的数字孪生。
在树状结构里选中一个元素,路径条将相应的调整,显示该元素的当前位置。在路径条最后的下拉框里选择“属性”,或在树状结构里,点击元素所在位置的三个点菜单,选择下拉菜单里的“属性”,系统将展示该元素的属性列表。
在属性列表的右上方,点击+,将创建一个新的属性。
属性可以配置名字、类别、数据类型、描述信息等。对于数值类型,您还可以对极限值、时序数据预测进行设置,也可以添加个性化的属性。属性还可以配置为常量、隐藏、不包含等。
属性支持丰富的数据类型,除了基本类型(Int、Double、Varchar 等)外还支持枚举类型和对象类型。对象类型包括文件类型、视频类型、属性类型和元素类型。文件类型属性的值可以是一个上传的文件或一个 URL,视频类型类似;属性类型的属性的值是另一个属性;元素类型的属性的值是另一个元素。
属性可以配置默认计量单位和显示计量单位。默认计量单位是采集量本身的计量单位,显示计量单位是页面上展示时使用的计量单位,如果默认计量单位和显示计量单位不一致,显示属性值的时候会自动做转换。比如默认单位是米,显示计量单位是公里,如果属性值是 1000,则会显示为 1km。默认计量单位和显示计量单位必须属于同一个计量单位分类(UOM Class)。
但最重要的是,属性可以配置数据引用 (Data Reference)。数据引用是指该属性值是由某个数据源推导出来的。数据引用可以是 TDengine 指标 或 TDengine 标签,它表示该属性实际指向 TDengine TSDB-Enterprise 里一张表的某一列,或一张表的标签值。本质上,引用是一个映射,它并没有复制数据,而是访问时,去从数据源 (比如 TDengine TSDB-Enterprise) 获取的。
属性的数据引用还支持计算公式 (Formula)、字符串生成器 (String Builder), 让数据引用更加灵活,来支持数据的标准化。计算公式是指该属性是基于其它属性的值计算出来的,比如智能电表的功率这个属性,是通过属性电流与属性电压相乘获得的,我们只需要配置计算的表达式即可。字符串生成器是指定一个字符串生成器的规则,基于几个字符串,构建出新的字符串。
今后属性的数据引用不仅能引用 TDengine TSDB-Enterprise 的数据,还能引用其它时序数据库或关系型数据库。
属性也可以被删除、修改、拷贝、粘贴等。
配置数据引用
这一节详细介绍如何配置属性的数据引用。所有数据引用都是通过一个字符串来设置的。在编辑属性的页面点击数据引用类型下面的输入框可进入数据引用编辑弹窗。
TDengine 指标和 TDengine 标签
TDengine 指标引用 TDengine TSDB-Enterprise 里一张表的某一列;TDengine 标签引用 TDengine TSDB-Enterprise 里一张表的标签值。它们的设置格式是:
连接名/数据库名/表名/列名(或标签名)
例如:
TDengine/idmp_sample_utility/em-17/location
其中 TDengine 是连接名,idmp_sample_utility 是数据库名,em-17 是表名,location 是标签名。
公式
公式引用的设置是一个表达式。它最终会被转换成 TDengine 的 SQL 表达式通过 TDengien TSDB 执行。公式引用表达式是属性、操作符、替换参数、常量和函数的组合。它引用的属性的类型必须是数值类型,它的输出也必须是数值。例如:
log(current) * voltage +10 + TIME
下图是公式引用表达式的配置示例:
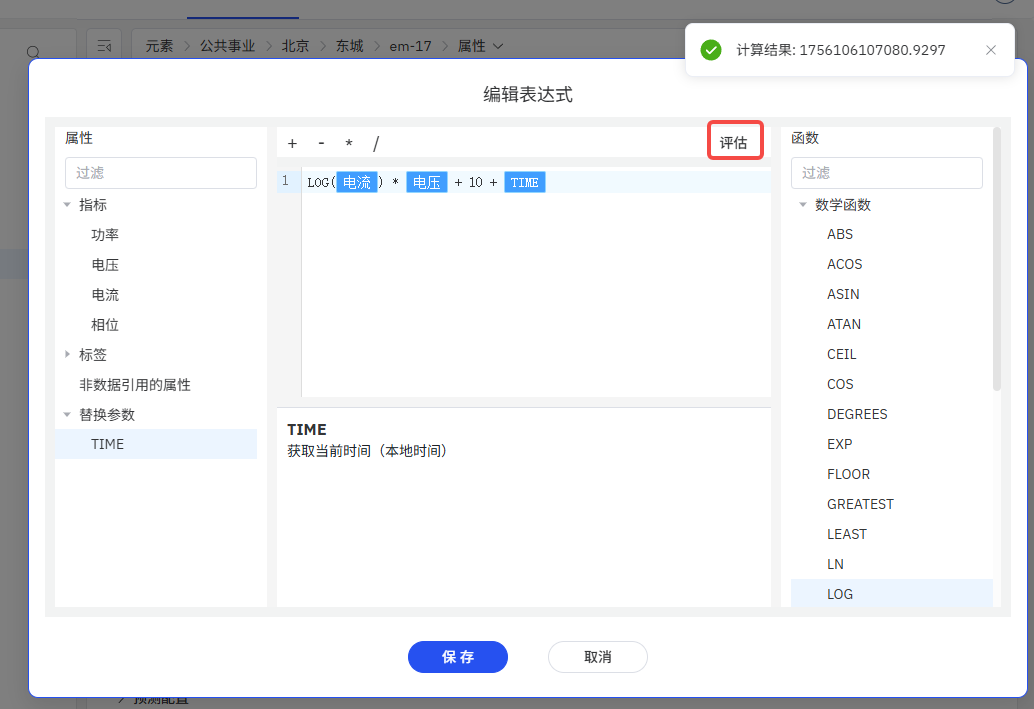
- 目前公式引用表达式可用的替换参数只有 TIME,它会被替换为当前本地时间对应的毫秒数。
- 目前公式引用表达式可引用的属性只能是当前元素的属性,如果要引用非本元素的属性 A,我们推荐的策略是给本元素增加一个新的属性 A', 使 A' 和 A 引用相同的外部数据。
在编辑表达式界面上,您随时可以点击“评估”来测试当前的表达式,IDMP 会对表达式进行合法性校验,如果校验通过会进一步尝试对其计算,如果计算异常对应的 SQL 语句和 SQL 异常都会抛出来,您可根据异常信息调整表达式。
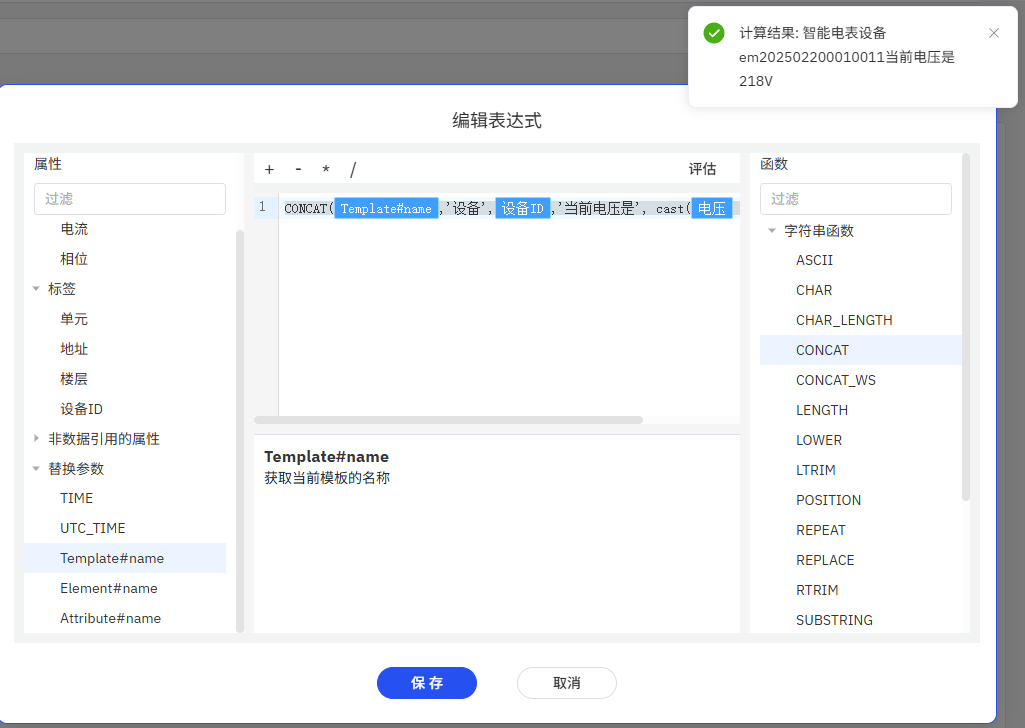
字符串生成器
字符串生成器引用的设置和公式引用的设置类似,也是一个表达式,只不过它的输出是字符串。它的输入可以是当前元素的任意属性,而不仅仅是数值类型的属性。常用的字符串操作函数有:
- CONCAT 用来拼接字符串
- SUBSTR 用来截取字符串
- CAST 用来将非字符串类型的列转成字符串类型
字符串生成器可用的替换参数也比较丰富,除了时间类替换参数,还有名称类替换参数,例如:当前元素名、当前属性名、当前元素使用的模板名。
不能使用加号拼接字符串,如果要拼接字符串请用公式编辑器界面右侧的 CONCAT 函数,CONCAT 函数的每一个参数也必须是字符串类型。如果要把数值类型的属性拼接到字符串,请先使用 CAST 函数转换,例如:CONCAT(地址,‘-’, CAST(电压 as varchar))
下图是一个字符串生成器引用的设置示例:
CONCAT(${Template#name},'设备',${attributes['设备 ID']},'当前电压是', cast(${attributes['电压']} as varchar), 'V')