3. 工业数据建模
工业智能化的地基,不是算法,而是数据模型。现实工厂中,企业 → 工厂 → 产线 → 设备 → 传感器构成层层嵌套的组织结构,每一层都承载着特定的业务含义。TDengine IDMP 通过工业数据建模将这套结构引入数字世界——为资产及其数据构建有序、可检索的知识目录,让原本散落在各处的数据孤岛连接成一个有血有肉的整体。
本章涵盖在 TDengine IDMP 中对工业环境进行数据建模所需的全部内容:从定义单个资产及其属性,到数据的情景化与标准化处理,到数据关联性与工业本体的构建,批量创建元素与属性,再到大规模资产目录的浏览与检索。
一次建模,处处受益。完善的数据模型不仅支撑精准的可视化展示和可靠的事件检测,更是 AI 洞察的前提——只有经过情景化的数据,才能成为真正的 AI 就绪数据资产,驱动跨团队的高效协作与持续的智能分析。
工业数据建模是什么
工业数据建模,是在数据存储层与数据应用层之间,构建一个统一的工业本体层。这一层本身并不存储任何原始数据,而是在原始数据之上,搭建一个让 AI 、应用和人都能理解、访问与使用的语义网络。
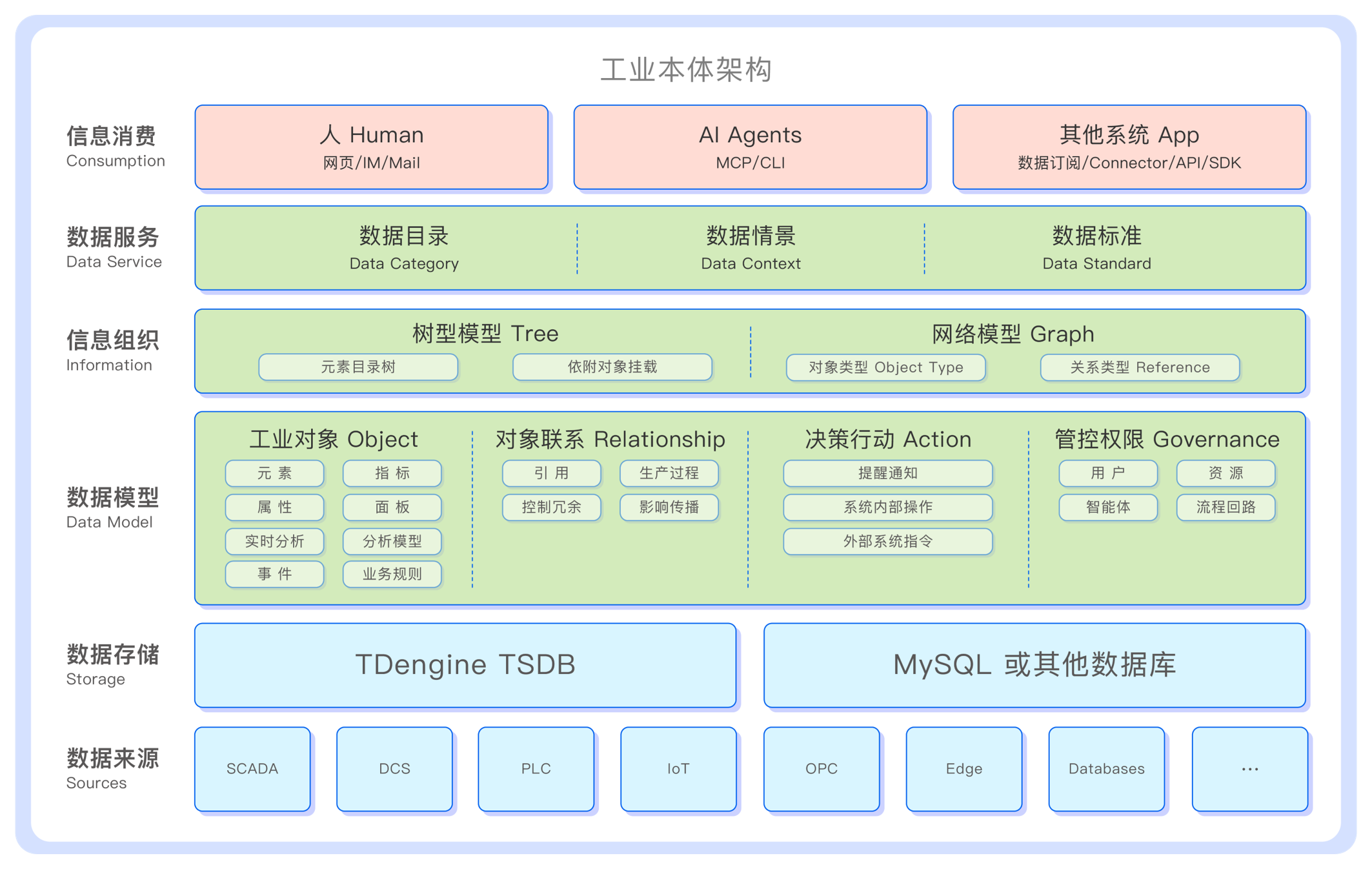
TDengine 构建的工业本体包含多层信息架构。
工业本体的基础是数据来源与数据存储层——工业本体本身不储存原始数据,工业场景下 SCADA、DCS、OPC 等工业系统持续产生原始监测信号,TDengine 以 TSDB 高性能时序数据引擎采集并存储这些海量数据。
随后是工业本体的核心——数据模型层,TDengine 从四个维度完整定义了工业世界数字对象的信息结构:
-
工业对象,即工业场景里需要被管理访问的对象,包括元素、属性、实时分析、事件、指标、面板、分析模型和业务规则。在 TDengine 的工业本体中,工业环境中的每一个物理或逻辑资产——工厂、产线、设备或传感器——都以元素的形式表示。元素是工业本体的基础构建单元,元素包含属性,属性变化触发实时分析进而产生事件,元素有统计指标和可视化面板,有相关的业务规则和分析模型。
-
对象联系,即工业对象之间的引用关系。元素与元素之间存在强引用、弱应用、组合应用等多种引用关系,属性依附于元素或事件,属性与属性之间存在引用计算和限值关联,分析与事件通过"引用"连接元素和属性,通过"触发"和"生成"串联起从监控到告警的链路,而模板与实例之间通过"派生"实现"一处定义、处处生效"。此外,元素与元素之间除了引用关系外,还有生产过程关系、控制冗余关系、影响传播关系,如生产流程中的上下游关系,联锁关系等;
-
决策行动,即元素和事件可以触发的动作与任务,如提醒通知、内部操作、外部指令等,TDengine 将所有可以"改变现实状态"的执行能力都收敛到全局统一管理的动作模板;
-
管控权限,即工业本体内部资源的权限管理,不同用户和智能体对不同资源拥有不同安全级别的访问与管理权限,对于特定敏感操作有明确的流程回路定义,如 Human in the Loop;
数据模型层之上是信息组织层,TDengine 用**树型模型(Tree)构建资产层级骨架,用网络模型(Graph)**补全跨层级的横向关系,树型模型与网络模型叠加,才构成完整的工业本体。
数据服务层将工业本体的信息转化为三类可对外提供的数据服务:数据目录屏蔽了底层数据的复杂性,让数据可发现、可检索、可治理;数据情景赋予每个数值业务语义,如单位、范围、归属、工况等,让数据可被理解;数据标准自动进行多源数据转换,确保数据标准与统计口径的全局一致性。
工业本体的这些数据服务,通过信息消费层提供给外部消费者——人通过零代码网页界面和自然语言问答访问数据,AI 智能体通过 MCP 遍历工业本体、调用平台能力,外部系统和应用通过 REST API、SDK 和消息队列集成数据。三类消费者、多种通道,共享同一份语义模型。
1. 一个面向 AI 、应用与人的数据门户
工业数据建模,首先是一个数据门户:它一头对接数据源,一头对接 AI 、应用和人三类不同的数据消费者,分别做接口适配,让每一类消费者都能用自己最自然的方式理解、访问与使用数据。
这一思路与业界讨论多年的 Data Fabric(数据编织)理念高度一致:通过元数据驱动的统一语义层,让数据摆脱物理位置的束缚,以"数据资产与数据服务"的形态被组织、被治理、被消费。在 IDMP 中:
- 数据 → 资产:原始时序点被赋予名称、单位、上下限、目标值、类别、位置和归属,从一串裸数字升级为可被业务理解的工程量。IDMP 在元素模板与属性模板中统一定义这些情景化字段,由模板派生到所有实例,做到"一处定义、处处生效"(参见 3.3 数据情景化);
- 数据集 → 资产库:分散的资产被统一归集到一棵可治理、可检索、可订阅、可授权的资产目录中,形成企业级的数据资产库。IDMP 以资产目录树作为统一入口,支持按路径下钻、按模板/分类/属性过滤,以及全文检索,并以子树为粒度做权限授权与共享(参见 3.7 元素与数据查询);
- 数据消费 → 服务化:人通过 Explorer 浏览、面板查看、AI 问答提问,系统通过 REST API / JDBC / ODBC / Kafka / MQTT 接入,AI Agent 通过 MCP 直接调用——三类消费者共享同一份语义模型。IDMP 把同一份数据模型,以原生 REST/JDBC/ODBC 接口、流式 Kafka/MQTT 订阅、以及面向 AI Agent 的 MCP 等方式对外提供数据服务,接口不同,但共享同一份基础数据(参见 15. 与其他系统集成)。
这是 IDMP 与传统时序库、传统组态平台最本质的区别:它管理的不是表与列,而是数据资产与语义关系。
2. 一份数据地图与数据目录
工业场景的数据来源非常丰富:有时序数据库(如 TDengine TSDB),有关系型数据库(如 MySQL),有各种工业生产流程与管理系统(如 MES、WMS、ERP 等),还有格式多样的文件系统(如文档、图片、视频等)。
工业数据建模的目标之一,就是要成为一份覆盖所有工业数据的数据地图与数据目录——它把分散在 TDengine TSDB、关系型数据库、工业流程系统,以及各种文件系统中的原始数据,映射到一棵或多棵由元素与属性组成的资产目录树上。
对上层应用来说,这一层屏蔽了底层数据的所有复杂性:
- 不需要关心数据存在哪个系统、哪个集群、哪个数据库、哪张表;
- 不需要关心数据类型是时序点、关系表,还是文件、图片、视频;
- 也不需要关心数据的命名规范、单位换算、采样频率的差异。
IDMP 通过统一的连接管理对接 TDengine TSDB、关系型数据库、OPC、MQTT、Kafka 等多种数据源,并以元素 + 属性的方式把它们映射到资产目录树上(参见 12. 数据接入)。上层应用只需要使用 IDMP 数据模型——/Elements/卷烟一厂/制丝车间/A线/烘丝段/薄板烘丝机-01/出口水分——去调用数据,IDMP 会完成后续必要的映射、转换与单位换算。原始数据被一次性"翻译"为包含业务语义的工程量。
3. 一张工业本体的数据关联网络
工业数据建模不止于数据映射,更重要的是——它建立并管理了数据之间的联系,让数据成为一个包含业务语义的有机整体,而不是彼此割裂的数据集。
工业现场充满了各种实体对象,这些对象之间存在着丰富而复杂的联系:
- 它们有层级关系(集团 → 工厂 → 产线 → 设备 → 测点),也有上下游关系(原料 → 真空回潮 → 烘丝 → 加香 → 储丝);
- 一个对象可以拥有多个父对象和多个子对象——一台风机既属于"某地理区域",又属于"某设备类型库";一个公共风量测点会同时影响多条工艺线。IDMP 通过强引用、弱引用、组合引用等多种引用形式,表达这些不同强度、不同语义的联系。
- 对象都带有属性,属性可以来自不同的数据源;属性既可以是对象的某个评估维度(测量值 / 标签),也可以是某个业务统计 KPI;属性的取值可以是数值、布尔等基础类型,可以是枚举类型,也可以是对象类型(文件、图片、视频、属性引用、元素引用等)。
- 对象之间、属性之间、对象与属性之间的所有这些联系,统称为 Reference(引用);每一种 Reference 都附带一个 Reference Type(引用类型),用于说明这条联系的业务语义。
- 围绕这些对象与属性,IDMP 还提供面板、仪表板、分析、事件、注解、文档等一系列描述信息与功能模块,作为不同视角下的信息消费入口,挂载在工业场景的对象节点之上。
所有这一切共同构成了一张复杂的工业本体网络——它看上去是一棵简单的 Tree,实际上 Far Beyond Tree,是一张具备业务语义的 Networking。这张网络,就是现实工业世界在数字空间中的虚拟镜像,也是 IDMP 实现工业本体的基础。
IDMP 实现数据关联管理的详细说明,参见 3.5 数据关联与工业本体。
工业数据建模的覆盖范围
IDMP 所建设的这一工业数据模型,目标不只是时序数据,而是要覆盖所有工业数据——包括关系型业务数据、文件类工程资料、图像与视频,乃至外围系统的状态与事件。
在当前阶段,IDMP 产品已实现的能力主要围绕时序数据展开;未来会逐步扩展到更多数据类型、对接更多种类的数据源,最终实现对现实工业世界的完整覆盖。一旦完成,IDMP 提供的就不再只是"看时序数据的窗口",而是一套面向工业场景全要素的数据业务语义管理体系。
这套语义体系对 AI 、应用和人都有独立而重要的价值:
- 对人:业务人员、工程师、运维和管理者,可以脱离系统术语,直接用业务语言(元素名、属性名、工艺段名)阅读、查询和讨论数据。
- 对应用:上层应用(BI、MES、APS、第三方分析工具等)通过一致的语义接口取数,不再为每一个数据源单独写适配;数据模型升级时应用自动适配,无需改造。
- 对 AI:这套语义体系真正释放价值的舞台。
这套体系对 AI 的独特价值
AI 对数据有一项独特的需求:它不仅要"取得到"数据,更要"看得懂"数据。没有语义的数据,对 AI 而言就是噪声——一个 4.7 的读数,如果不知道它是哪台电机的振动值、单位是什么、正常范围在哪,AI 唯一能做的就是"幻觉"。
让 AI 真正理解工业数据,至少需要四件事,而这四件事恰好都由 IDMP 的语义体系统一提供:
- 稳定的对象身份 —— 元素不是一串字符串,而是有路径、有模板、有归属、有上下游的"业务实体"。AI 推理时面对的是
薄板烘丝机-01,而不是tag_7831。 - 完整的数据情景 —— 工程单位、上下限、目标值、类别、运行工况、关联文档、历史事件,共同构成了 AI 判断"当前是否正常""偏离意味着什么"的输入。
- 可遍历的关联网络 —— 当 AI 做根因分析、影响分析时,它沿着 Reference 在元素—属性—事件—面板组成的网络中遍历,定位上下游、找到相似事件、检索关联资料。
- 统一的访问接口 —— 通过 MCP(Model Context Protocol),AI Agent 用同一套协议即可访问任意元素、任意属性、任意分析、任意事件,无需为每个数据源单独适配。
正因为这套语义体系存在,IDMP 上的 AI 智能体才能在毫秒级跨越分散的数据源与异构系统,完成理解 → 推理 → 回答 → 行动的完整闭环。这也正是 TDengine "AI 时代的工业数据基座"这一定位的真正内涵:工业数据建模,是 AI 在工业场景真正落地的基础能力与前提条件。
本章内容
本章后续小节将逐层展开这套语义体系的构建方法:
📄️ 元素与数据目录
在 TDengine IDMP 中,工业环境中的每一个物理或逻辑资产——工厂、产线、设备或传感器——都以元素的形式表示。元素是资产模型的基础构建单元,为原始时序数据提供了结构化的归属和有意义的上下文。
📄️ 属性
属性定义了元素的可测量特性。它是物理资产行为与 TDengine TSDB 中存储数据之间的桥梁——将原始数值转化为有名称、有类型、有物理单位的工程量。
📄️ 数据情景化
数据库表中名为 current 的列只是一个数字。只有当您知道是哪个电表产生了它、该电表安装在哪里、值的物理单位是什么,以及什么范围属于正常,它才变得有意义。数据情景化是将这些背景知识附加到数据上的过程——将原始测量值转化为丰富、可查询、AI 就绪的工业数据资产。
📄️ 数据标准化
工业环境通常从多个数据源采集数据,这些数据往往命名不一致、物理单位各异、数据结构不同。如果没有标准化,跨资产分析、AI 生成洞察和数据汇聚将变得不可靠甚至无法实现。TDengine IDMP 提供了多种机制,对整个资产模型中的数据进行标准化。
📄️ 数据关联与工业本体
本节为进阶话题。大多数用户可以跳过此节,待需要构建复杂数据模型时再回来阅读。
📄️ 批量创建元素与属性
批量创建元素与属性,是很多用户关心的一个实际问题。真实场景包含成千上万的元素与属性,不可能一个一个手工创建。
📄️ 元素与数据查询
随着资产模型不断扩展,快速定位所需元素或属性变得至关重要。TDengine IDMP 提供了多种互补的方式来导航和搜索资产目录:浏览元素树、按关键词或过滤条件搜索、将搜索结果保存为可复用的元素过滤器,以及将常用元素加入自定义分组以便快速访问。









